Yandex 代码库的“片段”上周在网上泄露。与 Google 类似,Yandex 是一个包含电子邮件、地图、出租车服务等多个方面的平台。此次代码泄露包含了所有这些内容。
根据其中的文档,Yandex 的代码库在 2013 年被合并到一个名为 Arcadia 的大型存储库中。泄露的代码库是 Arcadia 所有项目的子集,我们在“内核”、“库”、“机器人”、“搜索”和“ExtSearch”档案中找到了与搜索引擎相关的几个组件。
此举是史无前例的。自 2006 年 AOL 搜索查询数据以来,还没有哪项与网络搜索引擎相关的内容进入公共领域。
虽然我们缺少数据和许多引用的文件,但这是第一次切实了解现代搜索引擎在代码级别的工作方式。
就我个人而言,当我完成我的书“SEO的科学”时,我无法忘记能够真正看到代码是多么美妙的时机,我在书中讨论了信息检索、现代搜索引擎的实际工作方式以及如何自己构建一个简单的搜索引擎。
无论如何,我从上周四开始就一直在分析代码,任何工程师都会告诉你,这段时间不足以理解一切是如何运作的。所以,我猜随着我不断修改代码,还会有更多帖子。
在我们开始之前,我想感谢Ontolo 的Ben Wills与我分享代码,为我指明了好东西的初始方向,并在我们破译过程中与我反复沟通。欢迎在此处获取包含我们收集的有关排名因素的所有数据的电子表格。
另外,还要感谢Ryan Jones深入研究并通过即时通讯与我分享一些关键发现。
好啦,开始忙吧!
这不是 Google 的代码,我们为何要关心?
有些人认为,审查此代码库会分散注意力,而且不会影响他们做出业务决策的方式。我觉得这很奇怪,因为这些人来自同一个 SEO 社区,该社区使用 2006 年 AOL 数据的 CTR 模型作为多年来所有搜索引擎建模的行业标准。
话虽如此,Yandex 不是 Google。但这两家公司都是最先进的网络搜索引擎,一直处于技术前沿。
两家公司的软件工程师都会参加相同的会议(SIGIR、ECIR 等),并分享信息检索、自然语言处理/理解和机器学习方面的发现和创新。Yandex 在帕洛阿尔托也有办事处,而谷歌之前在莫斯科也有办事处。
通过 LinkedIn 快速搜索可以发现,有数百名工程师曾在两家公司工作过,但我们不知道其中有多少人实际上曾在两家公司从事搜索工作。
在更直接的重叠中,Yandex 还利用了 Google 的开源技术,这些技术对于搜索领域的创新至关重要,例如 TensorFlow、BERT、MapReduce 以及在较小程度上还有 Protocol Buffers。
因此,虽然 Yandex 肯定不是 Google,但它也不是我们在这里谈论的某个随机研究项目。通过查看这个代码库,我们可以学到很多关于现代搜索引擎如何构建的知识。
至少,我们可以摆脱一些仍然渗透在 SEO 工具中的过时观念,例如文本与代码比率和 W3C 合规性,或者普遍认为谷歌的 200 个信号仅仅是 200 个单独的页内和页外功能,而不是可能使用数千个单独措施的复合因素类别。
Yandex 架构的一些背景信息
如果没有上下文或成功编译、运行和单步执行的能力,源代码就很难理解。
通常,新工程师会获得文档、演练,并参与结对编程,以加入现有代码库。此外,文档档案中有一些与设置构建流程相关的有限入职文档。然而,Yandex 的代码也引用了内部 wiki,但这些都没有泄露,代码中的注释也相当稀少。
幸运的是,Yandex 在其公开文档中提供了一些有关其架构的见解。他们还在美国公布了几项专利,有助于阐明一些问题。即:
- 用于搜索具有多个发布列表的倒排索引的计算机实现方法和系统
- 搜索结果排序器
在为写书研究 Google 的过程中,我通过各种白皮书、专利和工程师针对我的 SEO 经验发表的演讲,对其排名系统的结构有了更深入的了解。我还花了很多时间来加深对网络搜索引擎的一般信息检索最佳实践的掌握。毫不奇怪,Yandex 确实有一些最佳实践和相似之处。
<img class="wp-image-392395 entered exited" src="data:;base64,” alt=”Yandex 爬虫系统” width=”800″ height=”376″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-crawler-system.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-crawler-system-600×282.png.webp 600w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-crawler-system-200×94.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-crawler-system-768×361.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-crawler-system-150×71.png.webp 150w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-crawler-system.png.webp” />
Yandex 的文档讨论了双分布式爬虫系统。一个用于实时爬取,称为“Orange Crawler”,另一个用于常规爬取。
据说,谷歌曾将索引分为三个部分:一个用于存放实时抓取的内容,一个用于存放定期抓取的内容,一个用于存放很少抓取的内容。这种方法被认为是 IR 中的最佳实践。
Yandex 和 Google 在这方面有所不同,但由对更新频率的理解驱动的分段爬行的总体思想是成立的。
值得一提的是,Yandex 没有单独的 JavaScript 渲染系统。他们在文档中提到了这一点,尽管他们有一个基于 Webdriver 的可视化回归测试系统 Gemini,但他们仅限于基于文本的抓取。
<img class="wp-image-392400 entered exited" src="data:;base64,” alt=”Yandex 搜索数据库” width=”800″ height=”318″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-search-database.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-search-database-600×239.png.webp 600w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-search-database-200×80.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-search-database-768×305.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-search-database-150×60.png.webp 150w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-search-database.png.webp” />
该文档还讨论了将页面分解为倒排索引和文档服务器的分片数据库结构。
与大多数其他网络搜索引擎一样,索引过程会构建字典、缓存页面,然后将数据放入倒排索引中,以便表示二元组和三元组及其在文档中的位置。
这与谷歌的不同之处在于,他们很久以前就转向了基于短语的索引,这意味着 n-gram 可以比三元组长得多。
然而,Yandex 系统也在其管道中使用BERT ,因此在某些时候文档和查询会转换为嵌入,并采用最近邻搜索技术进行排名。

排名过程让事情变得更加有趣。
Yandex 有一个称为元搜索的层,在处理查询后,缓存的热门搜索结果将在此层提供。如果未找到结果,则搜索查询将同时发送到基本搜索层中的数千台不同机器。每台机器都会构建相关文档的发布列表,然后将其返回到 Yandex 的神经网络应用程序 MatrixNet 进行重新排名,以构建 SERP。
根据 Google 工程师谈论搜索基础设施的视频,该排名流程与 Google 搜索非常相似。他们谈到 Google 的技术处于共享环境中,其中每台机器上都有各种应用程序,并且根据计算能力的可用性将作业分配到这些机器上。
其中一个用例就是将查询分发到各种机器上,以快速处理相关的索引分片。计算发布列表是我们需要考虑排名因素的第一步。
代码库中有 17,854 个排名因素
泄密事件发生后的周五,独一无二的 Martin MacDonald 热切地分享了代码库中的一个名为 web_factors_info/factors_gen.in 的文件。该文件来自代码库泄密事件中的“内核”档案,包含 1,922 个排名因素。
自然,SEO 社区已经利用这个数字和这个文件热切地传播其中的见解。许多人已经翻译了描述并构建了工具或 Google 表格和 ChatGPT 来理解数据。所有这些都是社区力量的绝佳例子。然而,1,922 只是代码库中众多排名因素中的一组。

深入研究代码库后发现,Yandex 查询处理和排名系统的不同子集有许多排名因素文件。
梳理这些因素,我们发现实际上总共有 17,854 个排名因素。这些排名因素包括与以下内容相关的各种指标:
- 点击。
- 停留时间。
- 利用 Yandex 的 Google Analytics等效产品 Metrika。
<img class="wp-image-392403 entered exited" src="data:;base64,” alt=”Yandex 17854 排名因素” width=”555″ height=”600″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-17854-ranking-factors-555×600.png.webp 555w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-17854-ranking-factors-312×338.png.webp 312w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-17854-ranking-factors-104×113.png.webp 104w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-17854-ranking-factors-150×162.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-17854-ranking-factors.png.webp 585w” data-lazy-sizes=”(max-width: 555px) 100vw, 555px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-17854-ranking-factors-555×600.png.webp” />
还有一系列 Jupyter 笔记本,除了核心代码中的因素外,还包含另外 2,000 个因素。据推测,这些 Jupyter 笔记本代表工程师正在考虑将其他因素添加到代码库中的测试。同样,您可以通过此链接查看所有这些功能以及我们从代码库中收集的元数据。
<img class="wp-image-392404 entered exited" src="data:;base64,” alt=”Yandex 排名公式” width=”450″ height=”187″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-formula.png.webp 450w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-formula-200×83.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-formula-150×62.png.webp 150w” data-lazy-sizes=”(max-width: 450px) 100vw, 450px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-formula.png.webp” />
Yandex 的文档进一步阐明了他们有三类排名因素:静态、动态以及与用户搜索及其执行方式特别相关的因素。用他们自己的话说:
<img class="wp-image-392405 entered exited" src="data:;base64,” alt=”Yandex 文档排名因素类别” width=”800″ height=”179″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes-800×179.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes-600×134.png.webp 600w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes-200×45.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes-768×172.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes-150×34.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes.png.webp 1029w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-documentation-ranking-factor-classes-800×179.png.webp” />
在代码库中,排名因素文件中使用标签 TG_STATIC 和 TG_DYNAMIC 来指示这些因素。搜索相关因素有多个标签,例如 TG_QUERY_ONLY、TG_QUERY、TG_USER_SEARCH 和 TG_USER_SEARCH_ONLY。
虽然我们已经发现了 18k 个潜在的排名因素可供选择,但与 MatrixNet 相关的文档表明,评分是根据数万个因素构建的,并根据搜索查询进行定制。
<img class="wp-image-392406 entered exited" src="data:;base64,” alt=”Matrixnet Yandex 文档” width=”800″ height=”283″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation-800×283.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation-600×212.png.webp 600w,https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation-200×71.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation-768×272.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation-150×53.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation.png.webp 1057w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/matrixnet-yandex-documentation-800×283.png.webp” />
这表明排名环境是高度动态的,类似于 Google 环境。根据 Google 的“评估评分函数框架”专利,他们早就有类似的东西,其中运行多个函数并返回最佳结果集。
最后,考虑到文档引用了数以万计的排名因素,我们还应该记住,代码中引用的许多其他文件在档案中缺失。因此,可能还有更多我们无法看到的事情。通过查看入门文档中的图像可以进一步说明这一点,这些图像显示了档案中不存在的其他目录。
<img class="wp-image-392407 entered exited" src="data:;base64,” alt=”入职文档 缺失目录 Yandex” width=”800″ height=”503″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-800×503.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-538×338.png.webp 538w,https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-180×113.png.webp 180w,https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-768×483.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-1536×965.png 1536w,https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-150×94.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex.png.webp 1999w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/onboarding-documentation-missing-directories-yandex-800×503.png.webp” />
例如,我怀疑 /semantic-search/ 目录中还有更多与 DSSM 相关的内容。
排名因素的初始权重
我最初假设代码库没有任何排名因素的权重。然后我惊讶地发现 /search/relevance/ 目录中的 nav_linear.h 文件完整显示了与排名因素相关的初始系数(或权重)。
这部分代码突出显示了我们已识别的 17,000 多个排名因素中的 257 个。(感谢 Ryan Jones 提取这些内容并将它们与排名因素描述对齐。)
为了清楚起见,当您想到搜索引擎算法时,您可能会想到一个长而复杂的数学方程,该方程根据一系列因素对每个页面进行评分。虽然这过于简单,但以下屏幕截图是此类方程的摘录。系数表示每个因素的重要性,计算出的分数将用于对选择器页面的相关性进行评分。
<img class="wp-image-392408 entered exited" src="data:;base64,” alt=”Yandex 相关性评分” width=”554″ height=”600″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring-554×600.png.webp 554w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring-312×338.png.webp 312w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring-104×113.png.webp 104w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring-768×832.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring-150×162.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring.png.webp 965w” data-lazy-sizes=”(max-width: 554px) 100vw, 554px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-relevance-scoring-554×600.png.webp” />
这些值是硬编码的,这表明这肯定不是排名发生的唯一地方。相反,这个函数最有可能是进行初始相关性评分的地方,以便为每个要考虑排名的分片生成一系列发布列表。在上面列出的第一个专利中,他们将其作为查询独立相关性 (QIR) 的概念来讨论,然后在审查查询特定相关性 (QSR) 之前限制文档。
然后将生成的发布列表连同查询特征一起传递给 MatrixNet 以供比较。因此,虽然我们尚不清楚下游操作的具体细节,但了解这些权重仍然很有价值,因为它们会告诉您页面符合考虑集的要求。
然而,这引出了下一个问题:我们对 MatrixNet 了解多少?
内核档案中有神经排名代码,并且整个代码库中有很多对 MatrixNet 和“mxnet”的引用,以及对深度结构化语义模型 (DSSM) 的许多引用。
FI_MATRIXNET 排名因子之一的描述表明 MatrixNet 适用于所有因子。
因素 {
指数:160
Cpp名称:“FI_MATRIXNET”
名称:“MatrixNet”
标签:[TG_DOC、TG_DYNAMIC、TG_TRANS、TG_NOT_01、TG_REARR_USE、TG_L3_MODEL_VALUE、TG_FRESHNESS_FROZEN_POOL]
描述:“MatrixNet 应用于所有因素——公式”
}
还有一堆二进制文件可能是预先训练的模型本身,但我需要更多时间来解开代码的这些方面。
一目了然的是,排名有多个级别(L1、L2、L3),并且每个级别都有多种排名模型可供选择。
<img class="wp-image-392410 entered exited" src="data:;base64,” alt=”Yandex 排名模型 1″ width=”730″ height=”600″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1-730×600.png.webp 730w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1-411×338.png.webp 411w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1-138×113.png.webp 138w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1-768×631.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1-150×123.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1.png.webp 1295w” data-lazy-sizes=”(max-width: 730px) 100vw, 730px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-ranking-models-1-730×600.png.webp” />
selecting_rankings_model.cpp 文件表明,在整个过程中,每一层都可能考虑不同的排名模型。这基本上就是神经网络的工作原理。每个级别都是完成操作的一个方面,它们的组合计算会产生重新排序的文档列表,最终显示为 SERP。当我有更多时间时,我会深入研究 MatrixNet。对于那些需要先睹为快的人,请查看搜索结果排名器专利。
现在,让我们来看看一些有趣的排名因素。
排名前 5 位的负面权重初始排名因素
以下是具有最高负权重的初始排名因素及其权重的列表,以及基于从俄语翻译的描述的简要解释。
- FI_ADV: -0.2509284637 – 该因素确定页面上是否存在任何类型的广告,并对单个排名因素发出最重的加权惩罚。
- FI_DATER_AGE: -0.2074373667 – 此因子是当前日期与 dater 函数确定的文档日期之间的差值。如果文档日期与今天相同,则值为 1;如果文档已有 10 年或更久,或者日期未定义,则值为 0。这表明 Yandex 偏爱较旧的内容。
- FI_QURL_STAT_POWER: -0.1943768768 – 此因素是与查询相关的 URL 展示次数。他们似乎想降低在许多搜索中出现的 URL 的排名,以促进结果的多样性。
- FI_COMM_LINKS_SEO_HOSTS: -0.1809636391 – 此系数是包含“商业”锚文本的入站链接的百分比。如果此类链接的比例超过 50%,则该系数恢复为 0.1,否则设置为 0。
- FI_GEO_CITY_URL_REGION_COUNTRY: -0.168645758 – 此因子是文档与用户搜索所在国家/地区的地理重合度。如果 1 表示文档与国家/地区匹配,则此因子不太有意义。
总而言之,这些因素表明,为了获得最佳分数,您应该:
- 避免广告。
- 更新旧内容而不是创建新页面。
- 确保大多数链接都有品牌锚文本。
此列表中的所有其他内容均不受您的控制。
排名前 5 位的正向加权初始排名因素
接下来,这里列出了权重最高的积极排名因素。
- FI_URL_DOMAIN_FRACTION: +0.5640952971 – 此因子是查询与 URL 域之间的奇怪掩蔽重叠。给出的示例是车里雅宾斯克彩票,缩写为 chelloto。为了计算此值,Yandex 会找到覆盖的三个字母(che、hel、lot、olo),看看所有三个字母组合在域名中所占的比例。
- FI_QUERY_DOWNER_CLICKS_COMBO: +0.3690780393 – 该因素的描述是“巧妙地结合了 FRC 和伪 CTR”。没有立即表明 FRC 是什么。
- FI_MAX_WORD_HOST_CLICKS: +0.3451158835 – 此因素是域中最重要的单词的可点击性。例如,对于所有包含单词“wikipedia”的查询,点击维基百科页面。
- FI_MAX_WORD_HOST_YABAR: +0.3154394573 – 因素描述为“根据栏目,与网站相对应的最具特征的查询词”。我假设这意味着与网站相关的 Yandex 工具栏中搜索次数最多的关键字。
- FI_IS_COM: +0.2762504972 – 该因素是域名为 .COM。
换句话说:
- 用你的域名玩文字游戏。
- 确保它是一个 .com。
- 鼓励人们在 Yandex Bar 中搜索您的目标关键词。
- 继续推动点击。
有很多意想不到的初始排名因素
初始加权排名因素中最有趣的是那些意想不到的因素。以下列出了 17 个引人注目的因素。
- FI_PAGE_RANK: +0.1828678331 – PageRank 是 Yandex 中第 17 大权重因素。他们之前已将链接从其排名系统中完全移除,因此它在列表中排名如此之低并不令人意外。
- FI_SPAM_KARMA: +0.00842682963 – Spam karma 以“反垃圾邮件发送者”命名,表示主机是垃圾邮件的可能性;基于 Whois 信息
- FI_SUBQUERY_THEME_MATCH_A: +0.1786465163 – 查询和文档在主题上的匹配程度。这是第 19 个最高加权因子。
- FI_REG_HOST_RANK: +0.1567124399 – Yandex 有一个主机(或域)排名因素。
- FI_URL_LINK_PERCENT: +0.08940421124 – 锚文本为 URL(而非文本)的链接与总链接数的比例。
- FI_PAGE_RANK_UKR: +0.08712279101 – 有一个特定的乌克兰 PageRank
- FI_IS_NOT_RU: +0.08128946612 – 如果域名不是 .RU,则是一件好事。显然,俄罗斯搜索引擎不信任俄罗斯网站。
- FI_YABAR_HOST_AVG_TIME2: +0.07417219313 – 这是 YandexBar 报告的平均停留时间
- FI_LERF_LR_LOG_RELEV: +0.06059448504 – 这是基于每个链接质量的链接相关性
- FI_NUM_SLASHES: +0.05057609417 – URL 中的斜线数量是排名因素。
- FI_ADV_PRONOUNS_PORTION: -0.001250755075 – 页面上代词名词的比例。
- FI_TEXT_HEAD_SYN: -0.01291908335 – 标题中存在[查询]单词,考虑到同义词
- FI_PERCENT_FREQ_WORDS: -0.02021022114 – 该语言中最常用的 200 个词的数量占文本所有词的数量的百分比。
- FI_YANDEX_ADV: -0.09426121965 – 更具体地说,对广告的厌恶,Yandex 会惩罚带有 Yandex 广告的页面。
- FI_AURA_DOC_LOG_SHARED: -0.09768630485 – 文档中非唯一的瓦片(文本区域)数量的对数。
- FI_AURA_DOC_LOG_AUTHOR: -0.09727752961 – 该文档所有者被识别为作者的瓦片数量的对数。
- FI_CLASSIF_IS_SHOP: -0.1339319854 – 显然,如果您的页面是商店,Yandex 会给您较少的关注。
通过查看这些奇怪的排名因素以及 Yandex 代码库中可用的各种排名因素,我们主要可以得出一个结论:有很多因素都可能成为排名因素。
我怀疑 Google 报告的“200 个信号”实际上是 200 个信号类别,每个信号都是由许多其他组件构成的复合体。就像 Google Analytics 具有与许多指标相关的维度一样,Google 搜索可能具有由许多特征组成的排名信号类别。
Yandex 抓取 Google、Bing、YouTube 和 TikTok 数据
代码库还显示,Yandex 拥有许多针对其他网站及其各自服务的解析器。对于西方人来说,其中最引人注目的就是我在上文标题中列出的那些。此外,Yandex 还拥有针对各种我不熟悉的服务以及针对其自身服务的解析器。
<img class="wp-image-392411 entered exited" src="data:;base64,” alt=”Yandex 解析器” width=”308″ height=”600″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-parsers-308×600.png.webp 308w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-parsers-173×338.png.webp 173w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-parsers-58×113.png.webp 58w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-parsers-150×292.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-parsers.png.webp 376w” data-lazy-sizes=”(max-width: 308px) 100vw, 308px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-parsers-308×600.png.webp” />
显而易见的是,解析器功能齐全。Google SERP 的每个有意义组件都已提取。事实上,任何可能考虑抓取这些服务的人都应该查看一下此代码。
<img class="wp-image-392413 entered exited" src="data:;base64,” alt=”Google 网页解析器 Yandex” width=”800″ height=”533″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex-800×533.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex-507×338.png.webp 507w,https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex-170×113.png.webp 170w,https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex-768×512.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex-150×100.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex.png.webp 1304w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/google-web-parser-yandex-800×533.png.webp” />
还有其他代码表明 Yandex 正在使用一些 Google 数据作为 DSSM 计算的一部分,但 Google 列出的 83 个排名因素本身就清楚地表明 Yandex 严重依赖 Google 的结果。
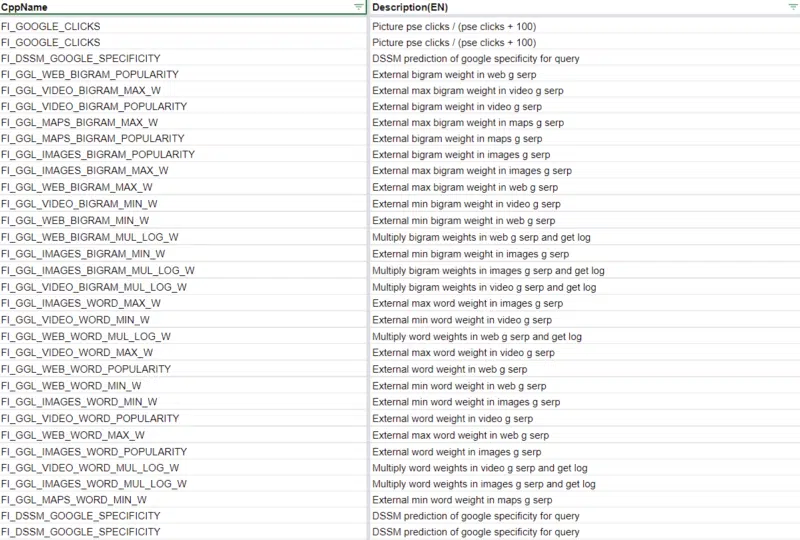
显然,谷歌永远不会像Bing 那样复制其他搜索引擎的搜索结果,也不会依赖其他搜索引擎进行核心排名计算。
Yandex 对某些排名因素设定了反 SEO 上限
315 个排名因素都有阈值,超过该阈值的任何计算值都会向系统表明该页面的该功能被过度优化。其中 39 个排名因素是初始加权因素的一部分,这些因素可能会阻止页面被列入初始发布列表。您可以通过筛选排名系数和反 SEO 列,在上面我链接的电子表格中找到这些内容。

从概念上来说,期望所有现代搜索引擎都对 SEO 过去滥用的某些因素(如锚文本、点击率或关键词堆砌)设置阈值并非天方夜谭。例如,据说 Bing 利用元关键词的滥用作为负面因素。
Yandex 增强“重要主机”功能
Yandex 在其代码库中拥有一系列提升机制。这些是对某些文档进行人为改进,以确保它们在考虑排名时获得更高的分数。
下面是来自“增强向导”的评论,它表明较小的文件最能从增强算法中受益。
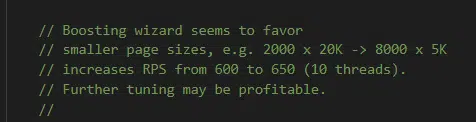
提升有多种类型;我见过一种与链接相关的提升,还见过一系列“HandJobBoosts”,我只能假设它是“手动”更改的奇怪翻译。
<img class="wp-image-392415 entered exited" src="data:;base64,” alt=”Handjobboosts Yandex” width=”800″ height=”234″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex-800×234.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex-600×176.png.webp 600w,https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex-200×59.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex-768×225.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex-150×44.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex.png.webp 947w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/handjobboosts-yandex-800×234.png.webp” />
我发现其中一个提升特别有趣,它与“重要主机”有关。其中重要主机可以是任何指定的站点。变量中特别提到的是 NEWS_AGENCY_RATING,这让我相信 Yandex 会将其结果偏向某些新闻机构。

不谈地缘政治,这与谷歌非常不同,因为他们一直坚持不将这样的偏见引入他们的排名系统。
文档服务器的结构
代码库揭示了文档在 Yandex 文档服务器中的存储方式。这有助于理解搜索引擎不会简单地复制页面并将其保存到缓存中,而是会捕获各种特征作为元数据,然后用于下游排名流程。
下面的屏幕截图突出显示了这些功能中特别有趣的一个子集。其他带有 SQL 查询的文件表明文档服务器有近 200 列,包括 DOM 树、句子长度、获取时间、一系列日期和反垃圾邮件分数、重定向链以及文档是否已翻译。我遇到的最完整的列表位于 /robot/rthub/yql/protos/web_page_item.proto。
<img class="wp-image-392419 entered exited" src="data:;base64,” alt=”Yandex Simhashes” width=”527″ height=”600″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes-527×600.png.webp 527w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes-297×338.png.webp 297w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes-99×113.png.webp 99w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes-768×875.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes-150×171.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes.png.webp 891w” data-lazy-sizes=”(max-width: 527px) 100vw, 527px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-simhashes-527×600.png.webp” />
此处子集中最有趣的是所采用的simhashes的数量。Simhashes 是内容的数字表示,搜索引擎使用它们进行闪电般快速的比较以确定重复内容。机器人档案中有各种实例表明重复内容被明确降级。
<img class="wp-image-392420 entered exited" src="data:;base64,” alt=”Yandex 重复内容” width=”800″ height=”101″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content-800×101.png.webp 800w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content-600×75.png.webp 600w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content-200×25.png.webp 200w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content-768×97.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content-150×19.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content.png.webp 1288w” data-lazy-sizes=”(max-width: 800px) 100vw, 800px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-duplicate-content-800×101.png.webp” />
此外,作为索引过程的一部分,代码库在其文本处理管道中采用了TF-IDF、BM25和 BERT。目前尚不清楚为什么所有这些机制都存在于代码中,因为使用它们都存在一些冗余。
链接因素和优先级
代码库还揭示了大量有关链接因素以及链接如何排序的信息。
Yandex 的链接垃圾邮件计算器会考虑 89 个因素。标记为 SF_RESERVED 的任何内容都将被弃用。如果提供,您可以在上面链接的 Google Sheet 中找到这些因素的描述。
<img class="wp-image-392421 entered exited" src="data:;base64,” alt=”Yandex 垃圾邮件因素” width=”457″ height=”600″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-457×600.png.webp 457w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-257×338.png.webp 257w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-86×113.png.webp 86w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-768×1008.png.webp 768w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-150×197.png.webp 150w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors.png.webp 815w” data-lazy-sizes=”(max-width: 457px) 100vw, 457px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-457×600.png.webp” />
<img class="wp-image-392422 entered exited" src="data:;base64,” alt=”Yandex 垃圾邮件因素 2″ width=”408″ height=”518″ data-lazy-srcset=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-2.png.webp 408w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-2-266×338.png.webp 266w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-2-89×113.png.webp 89w,https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-2-150×190.png.webp 150w” data-lazy-sizes=”(max-width: 408px) 100vw, 408px” data-lazy-src=”https://searchengineland.com/wp-content/seloads/2023/01/yandex-spam-factors-2.png.webp” />
值得注意的是,Yandex 拥有主机排名和一些分数,这些分数似乎在网站或页面被认定为垃圾信息后仍会长期存在。
Yandex 所做的另一件事是审查整个域中的副本,并确定这些链接是否有重复的内容。这可能是网站范围内的链接位置、重复页面上的链接,或者只是来自同一网站的具有相同锚文本的链接。

这说明了忽略来自同一来源的多个链接是多么简单,也阐明了从更多不同来源定位更多唯一链接是多么重要。
我们可以从 Yandex 中应用哪些关于 Google 的知识?
当然,这仍然是每个人心中的问题。虽然 Yandex 和 Google 之间确实有很多相似之处,但说实话,只有从事搜索工作的 Google 软件工程师才能明确回答这个问题。
但这是一个错误的问题。
确实,这段代码应该有助于我们拓展对现代搜索的思考。对搜索的集体理解大部分都来自 SEO 社区在 21 世纪初通过测试获得的知识以及搜索工程师的口中,当时搜索远没有那么不透明。不幸的是,这并没有跟上快速创新的步伐。
Yandex 泄密事件的诸多特点和因素所带来的见解应该能为 Google 排名提供更多可供测试和考虑的假设。他们还应该引入更多可以通过 SEO 抓取、链接分析和排名工具解析和衡量的内容。
例如,使用 BERT 嵌入来测量查询和文档之间的余弦相似度对于理解竞争对手的页面可能很有价值,因为这是现代搜索引擎自己正在做的事情。
就像 AOL 搜索日志让我们不再猜测 SERP 上的点击分布一样,Yandex 代码库让我们从抽象走向具体,我们的“视情况而定”语句可以更加合格。
为此,这个代码库是一份不断馈赠的礼物。这才一个周末,我们已经从这个代码中收获了一些非常引人注目的见解。
我预计一些雄心勃勃、有更多时间的 SEO 工程师会继续挖掘,甚至可能填补足够的空白,以编译并运行这个东西。我还相信不同搜索引擎的工程师也在研究和分析他们可以学习并添加到他们的系统中的创新。
与此同时,谷歌律师可能正在起草与所有抓取行为有关的严厉停止和终止信函。
我渴望看到我们的领域在那些好奇的人们的推动下发生演变,他们将最大限度地利用这一机会。
但是,嘿,如果从实际代码中获取见解对您来说没有价值,那么欢迎您回去做一些更重要的事情,例如争论子域名与子目录。