SEO 专家 Cindy Krum 表示,谷歌移动优先索引的第二阶段(渲染)是 Chrome,自 2018 年以来一直如此。在最近发布的视频演示中,Krum 表示:
- “我认为现在发生的事情是,谷歌在 2018 年推出时没有告诉我们,他们用于第二阶段索引的不是机器人本身。而是我们家里的电脑。您的 Chrome 被用作渲染资源。这意味着你。当有人请求该网站并执行 JavaScript 时,他们会从他们的计算机中获取它。他们不会使用他们的机器人来渲染它。他们会等到用户为他们渲染页面,然后他们就会去捕获整个页面的渲染,以便他们可以处理它。
- “……Google 使用我们自己的计算机来预处理信息以进行索引,并使用我们自己的浏览器来捕获信息并进行呈现。我们不一定选择加入这一行列,而且我们也不会故意获得任何回报。
- “…Google 还在使用我们的渲染数据和行为——在创建群组模型、主题模型、历史和参与度模型等方面——他们未经许可就从我们的本地计算机获取这些数据,并将其传递给他们的处理器。现在它在本地进行预处理,以便可以分批发送,然后将其发送到他们的算法中进行进一步处理和评估。这就是他们能够获得排名的方式,也是他们能够了解人口群组、旅程、购物地点等信息的方式,并做出决策、理解和建模,以便他们可以在PMax和 PPC 活动中的广告模型中使用这些数据。他们利用我们的行为向我们推销产品,并训练投放广告的人工智能,使其做得更好。”
简单来说两张幻灯片:
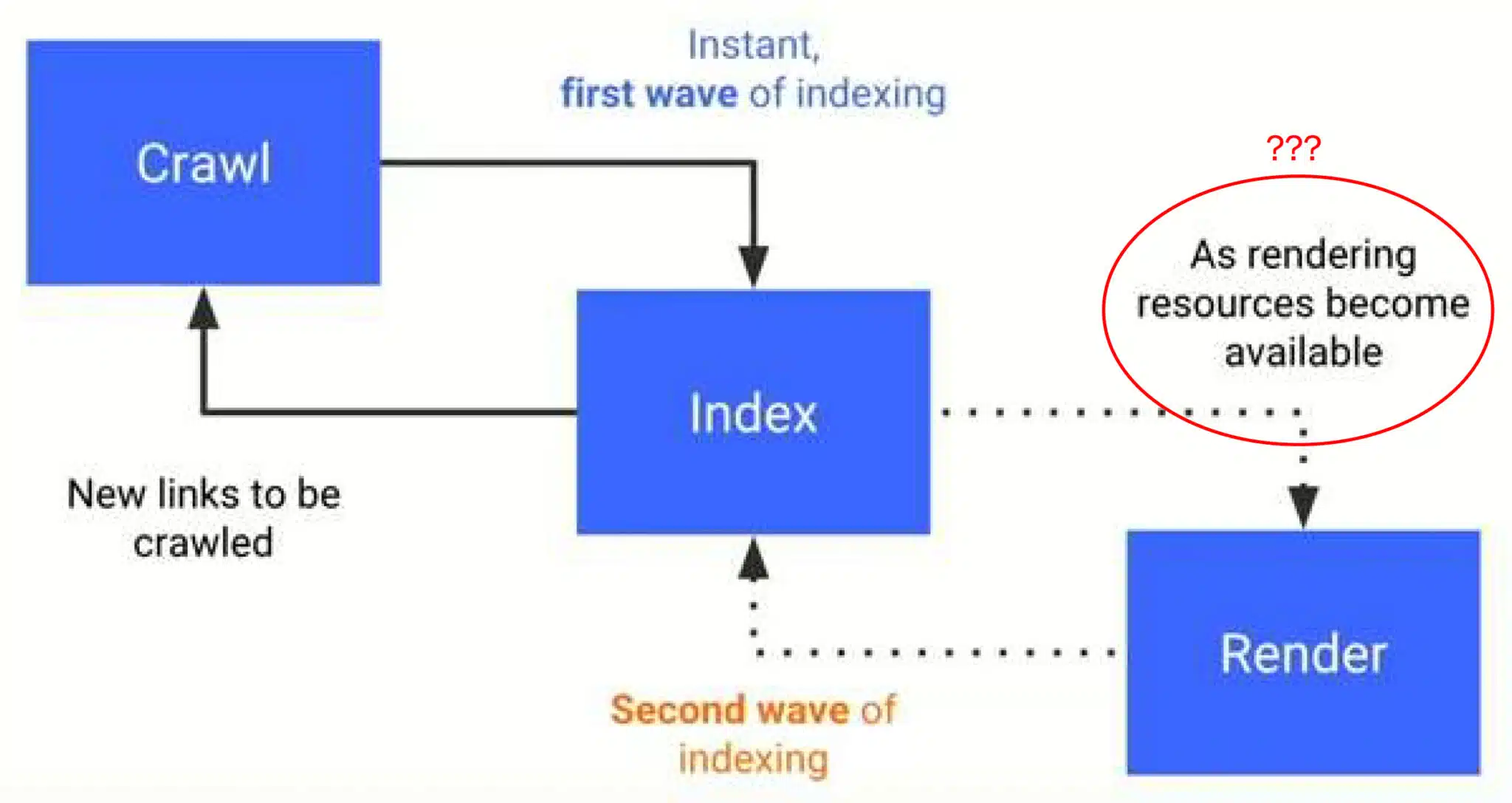
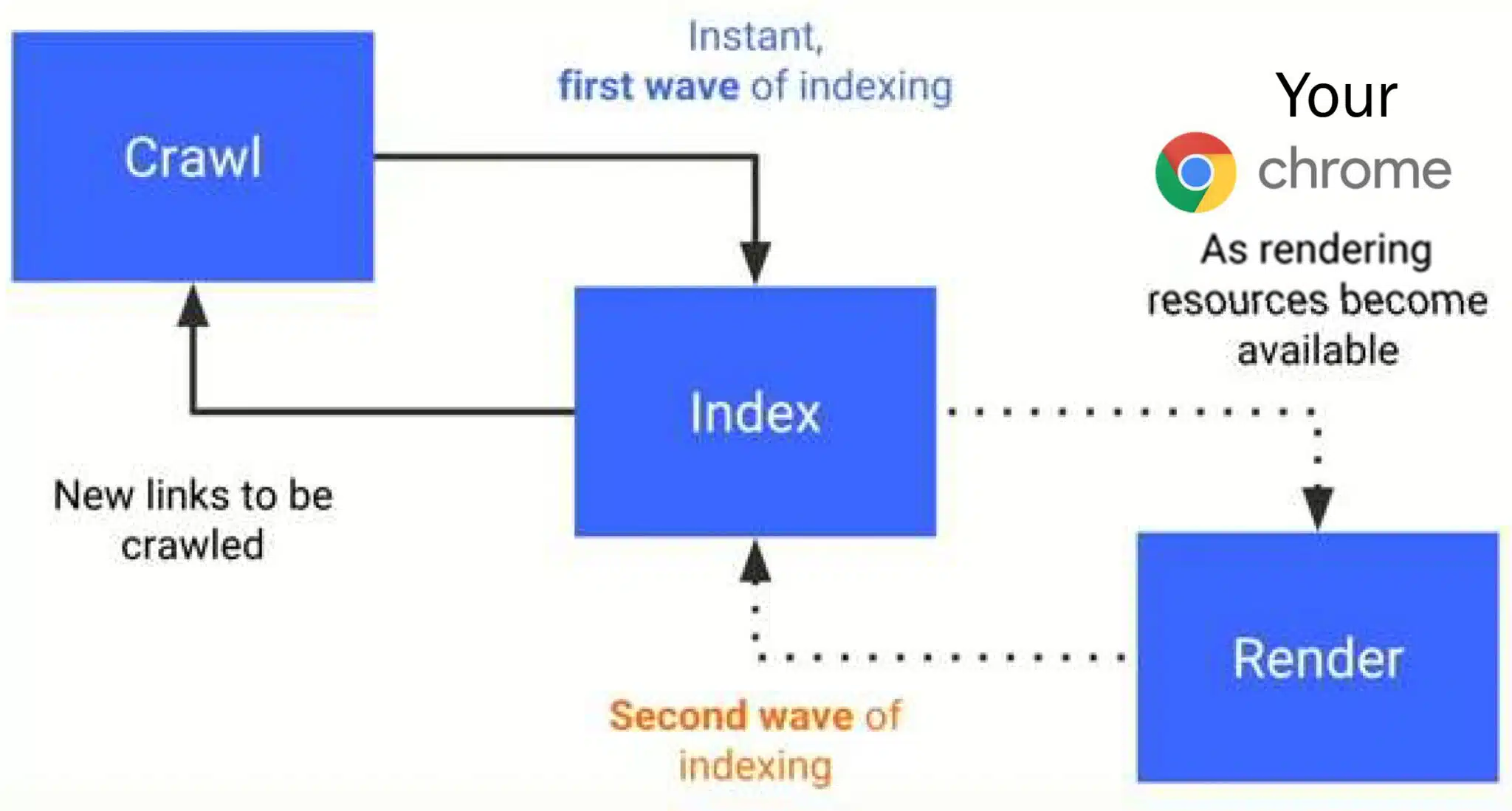
连接点。Krum的演讲中有很多关于谷歌转向移动优先索引的其他重大影响的说法,以及 Chrome 如何从本质上助长了谷歌的非法搜索垄断:
- 用户计算机作为资源:Google 使用用户的设备来呈现和处理 JavaScript,然后对其进行索引 – 本质上是将计算工作外包给用户。本质上,Google 使用 Chrome 的方式与你的计算机用于比特币挖掘的方式相同。
- 核心网络生命力:Google 捕获真实用户数据来评估页面加载性能和交互,并将这些数据输入其排名算法中。
- 浏览器更新和数据收集:频繁的 Chrome 更新确保数据收集与 Google 的搜索和广告模型保持一致,从而有助于定向广告和人工智能训练。
- 侵犯隐私:谷歌被发现索引私人数据(例如私人 WhatsApp 群组),这可能是由于其积极的缓存和数据收集做法。
- Chrome 在人工智能中的作用:人工智能非常昂贵,因此谷歌可以使用 Chrome 的处理模型来帮助人工智能开发,从而在人工智能军备竞赛中占据优势。
- 广告跟踪和定位:Google 的数据收集扩展到广告模型,例如用于广告优化的群组定位和用户行为建模。
- Cookie 和隐私:尽管 Google 承诺终止使用第三方 Cookie,但其仍在继续使用它们进行广泛的跟踪和数据收集。
可能对 SEO 产生影响。我联系了 Krum,问她如果所有这些都正确,那么可能对 SEO 产生什么影响。她告诉我:
- 如果某个网页包含从未被点击的链接,Google 就不太可能抓取该网页。理论上我们知道这一点,但现在我们对它的工作原理有了更好的了解。
- 真实的用户参与度可能比我们之前认为的更重要——自从谷歌搜索泄密事件以来我们就知道这一点。
- 如果在 Chrome 中发生 SERP 和点击信息的操纵,则是一个严重的漏洞。
- 实际用户渲染至关重要,因此为 GoogleBot 提供选择性服务可能不是一个很好的策略。
我们为什么关心这个问题。我们知道,谷歌从其其他各种服务(搜索、YouTube、广告等)收集了大量的 Chrome 和最终用户数据。话虽如此,需要明确的是,她讨论的大部分内容目前都是未经证实的理论(克鲁姆在演讲中确实使用了“锡箔”这个词,并且有多张“X 档案”主题的幻灯片)。
我第一次观看这段视频时,觉得它既荒诞、难以置信又完全可信。这需要花很多时间去消化。然而,鉴于司法部审判和泄密事件的所有披露,克鲁姆在视频中讨论的任何内容都不是过于疯狂的猜测。我很好奇谷歌是否会做出回应。
补充阅读。Krum还引用了前 Google 员工Malte Ubl 的研究,他表示“Google 使用最新版本的 Chrome 进行渲染”,他的研究发现“100% 的 HTML 页面都会导致整页渲染,包括具有复杂 JS 交互的页面。”
演示。观看视频并自行决定(我建议从 6:37 左右开始):Google 移动优先索引的第二阶段只是 Chrome。

批评。Pedro Dias 认为 Google 不太可能将 Chrome 用作索引的分布式渲染资源。他的LinkedIn 帖子(和评论)值得一读,Krum 对 Dias 的回应也值得一读。(顺便说一句,很高兴看到两个超级聪明的人进行了深思熟虑的讨论,而没有陷入混乱和毒性。我们需要更多这样的讨论!)