回顾搜索和 SEO 的历史,并预测互联网的下一次迭代对营销人员意味着什么。
今年是 20 年前,我写了一本书,名为《搜索引擎营销:基本最佳实践指南》。它被普遍认为是第一本关于SEO和信息检索 (IR) 底层科学的综合指南。
我认为回顾一下我在 2002 年写的内容,看看它今天如何,会很有用。我们将从爬取网络所涉及的基本方面开始。
了解互联网和搜索的历史和背景很重要,这样才能了解我们目前所处的位置以及未来会如何。而且我要告诉你,还有很多内容需要讲解。
我们的行业现在正飞速进入互联网的另一个新阶段。我们将首先回顾我在 2002 年所涵盖的基础工作。然后,我们将探索 SEO 的现状,着眼于未来,看看一些重要的例子(例如,结构化数据、云计算、物联网、边缘计算、5G),
所有这一切都是互联网诞生以来的一次巨大飞跃。
请和我一起回顾搜索引擎优化的记忆之路。
重要的历史课
我们交替使用万维网和互联网这两个术语。然而,它们并不是一回事。
你可能会惊奇地发现有很多人不明白其中的区别。
互联网的第一个版本发明于 1966 年。科学家文特·瑟夫(Vint Cerf,现任谷歌首席互联网推广员)于 1973 年发明了进一步的迭代,使其更接近我们现在所知的状态。
万维网是由英国科学家蒂姆·伯纳斯-李(现已获爵士称号)于 20 世纪 80 年代末发明的。
有趣的是,大多数人都认为,在他的发明问世之前,他花了相当于一生的时间进行科学研究和实验。但事实并非如此。1989 年的一天,伯纳斯-李在瑞士 CERN 实验室的员工咖啡馆吃火腿三明治时,利用午餐时间发明了万维网。
为了使本文的标题更加清晰,从第二年(1990 年)开始,网络就一直以这样或那样的方式被一个或另一个机器人抓取,直到今天(因此网络抓取已经有 32 年了)。
为什么你需要知道这些
网络从来就不是用来做我们现在所期望的事情的(而且这些期望越来越大)。
伯纳斯-李最初设想和开发万维网是为了满足世界各地大学和研究所的科学家之间自动共享信息的需求。
所以,我们试图让网络实现的很多功能对于发明者和浏览器(也是伯纳斯·李发明的)来说是陌生的。
这与搜索引擎在尝试收集内容进行索引和保持新鲜度,同时尝试发现和索引新内容时面临的可扩展性主要挑战非常相关。
搜索引擎无法访问整个网络
显然,万维网本身就存在挑战。这让我想到了另一个需要强调的极其重要的事实。
这是 Google 首次推出时开始出现的“普遍神话”,现在似乎和当时一样普遍。人们相信 Google 可以访问整个网络。
不。不对。事实上,根本不是。
1998 年,当 Google 首次开始抓取网络时,其索引中大约有 2500 万个唯一 URL。十年后的 2008 年,他们宣布已达到重要里程碑,即网络上有 1 万亿个唯一 URL。
最近,我看到一些数字表明 Google 知道大约 50 万亿个 URL。但我们 SEO 人员都需要知道以下重大区别:
- 了解大约 50 万亿个 URL 并不意味着它们都被抓取和编入索引。
50 万亿个 URL 数量可谓非常庞大。但这只是整个网络的一小部分。
Google(或任何其他搜索引擎)可以抓取网络表面上的大量内容。但“深层网络”上也有大量内容,抓取工具根本无法访问。它们被锁定在接口后面,导致数据库内容数量巨大。正如我在 2002 年强调的那样,抓取工具没有配备显示器和键盘!
此外,50 万亿个唯一 URL 这个数字是任意的。我不知道 Google 现在的真实数字是多少(他们自己也不知道万维网上到底有多少个页面)。
这些 URL 也并非全部指向唯一内容。网络上充斥着垃圾邮件、重复内容、无处可去的重复链接以及各种其他类型的网络垃圾。
- 这一切意味着什么:我使用的任意 50 万亿个 URL 这个数字本身只是网络的一小部分,其中只有一小部分最终被纳入 Google 的索引(和其他搜索引擎)以供检索。
了解搜索引擎架构
2002 年,我对“基于爬虫的搜索引擎的一般结构”进行了视觉解释:
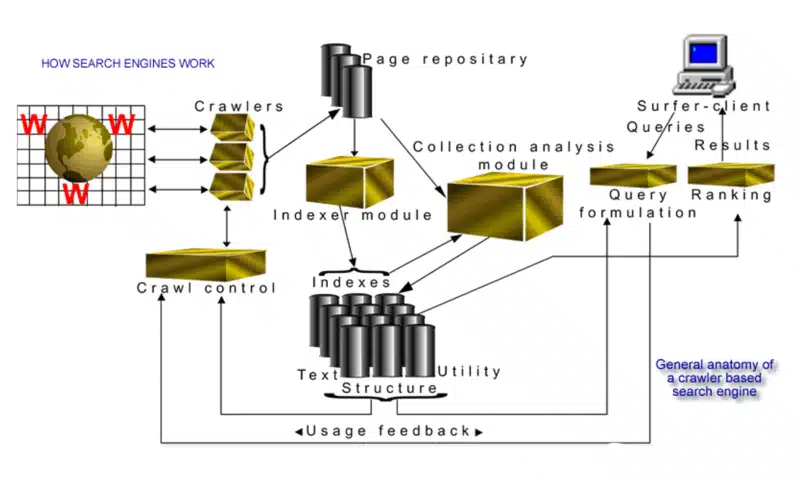
显然,这张图片并没有为我赢得任何平面设计奖项。但它准确地展示了 2002 年网络搜索引擎的各个组件是如何组合在一起的。它无疑帮助新兴的 SEO 行业更好地了解了该行业及其实践为何如此必要。
尽管搜索引擎使用的技术已经有了很大的进步(例如:人工智能/机器学习),但主要的驱动因素、流程和基础科学仍然保持不变。
尽管近年来“机器学习”和“人工智能”这两个术语越来越频繁地出现在行业词汇中,但我在 20 年前在搜索引擎结构部分中写过这样一段话:
“在本节的结论中,我将讨论‘学习机器’(矢量支持机)和人工智能(AI),这是网络搜索和检索领域下一步不可避免的发展方向。”
“新一代”搜索引擎爬虫
很难相信,全球只有少数几家通用搜索引擎在抓取网络数据,而谷歌(可以说是)最大的搜索引擎。我之所以这么说,是因为在 2002 年,当时有几十家搜索引擎,而且几乎每周都有新成立的搜索引擎。
由于我经常与业内更年轻的从业者交流,我仍然觉得很有趣的是,许多人甚至没有意识到在 Google 出现之前 SEO 就已经存在。
尽管谷歌因其在网络搜索方面的创新方式而备受赞誉,但它也从一个叫布莱恩·平克顿的人身上学到了很多东西。我有幸采访过平克顿(不止一次)。
他是世界上第一个全文检索搜索引擎 WebCrawler 的发明者。尽管他在搜索行业刚刚起步时就已经走在了时代的前面,但当他向我解释他的第一个网络搜索引擎设置时,我还是忍俊不禁。它运行在一台 486 机器上,有 800MB 的磁盘和 128MB 的内存,还有一个爬虫程序,可以下载和存储来自 6,000 个网站的页面!
这与我在 2002 年写的关于谷歌的文章有些不同,我认为谷歌是一个爬行网络的“新一代”搜索引擎。
“‘爬虫’这个词几乎总是以单数形式使用;然而,大多数搜索引擎实际上都拥有多个爬虫,并拥有一个大规模执行工作的‘舰队’代理。例如,作为新一代搜索引擎,谷歌一开始就拥有四个爬虫,每个爬虫保持大约三百个连接开放。在峰值速度下,它们每秒下载超过一百个页面的信息。谷歌(在撰写本文时)现在依靠 3,000 台运行 Linux 的 PC,拥有超过 90 TB 的磁盘存储空间。他们每天向服务器群添加三十台新机器,只是为了跟上增长的速度。”
自从我写下这篇文章以来,谷歌的扩张和增长模式一直在持续。我已经有一段时间没有看到准确的数字了,但也许几年前,我看到过一个估计,谷歌每天抓取 200 亿个网页。现在可能还会更多。
超链接分析和抓取/索引/整个网络难题
如果您的网页从未被抓取过,是否有可能进入 Google 前十名?
虽然这个问题看上去不太可能,但答案是肯定的。这也是我在 2002 年的书中提到的内容:
有时,Google 会返回一个列表,甚至是指向某个文档的单个链接,该文档尚未被抓取,但会发出通知,指出该文档之所以出现,是因为关键字出现在指向该文档的其他带有链接的文档中。
这是怎么回事?这怎么可能?
超链接分析。没错,这就是反向链接!
抓取、索引和仅仅了解唯一 URL 之间是有区别的。以下是我给出的进一步解释:
“如果您回顾在网络爬取部分中概述的巨大挑战,就会发现,在搜索引擎蜘蛛访问后,您永远不应假设您的网站上的所有页面都已被编入索引。我有一些客户的网站页面数量各不相同。有的有 50 个,有的有 5,000 个,老实说,我可以说,没有一个网站的每个页面都被所有主要搜索引擎编入索引。所有主要搜索引擎的 URL 都处于众所周知的爬取“边界”上,即爬虫控制数据库中经常有数百万个 URL,它知道这些 URL 存在,但尚未被爬取和下载。”
我见过很多次这样的例子。查询后的前 10 个结果有时会显示一个基本 URL,而没有标题或摘要(或元数据)。
这是我在 2004 年的一次演示中使用过的一个示例。看看下面的结果,您就会明白我的意思。
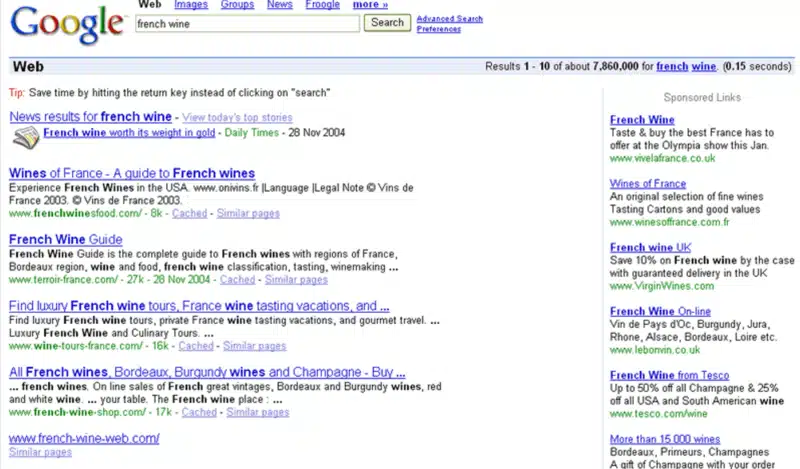
Google 知道该页面的重要性,因为它周围有链接数据。但是没有从该页面提取任何支持信息,甚至没有提取标题标签,因为该页面显然尚未被抓取。(当然,当有人留下 robots.txt 文件阻止网站被抓取时,这种情况也可能会发生,这种小失误仍然时有发生。)
我用粗体标出了上面的那句话,有两个重要原因:
- 超链接分析可以在网页被抓取和索引之前就指出其“重要性”。除了带宽和礼貌之外,网页的重要性是规划抓取的三个主要考虑因素之一。(我们将在以后的文章中深入探讨超链接和基于超链接的排名算法。)
- 时不时地,“链接是否仍然重要”的争论会爆发(然后逐渐平息)。相信我。答案是肯定的,链接仍然很重要。
我只是想稍微修饰一下“礼貌”这个词,因为它与 robots.txt 文件/协议直接相关。我 20 年前解释过的所有抓取网络的挑战今天仍然存在(规模更大)。
由于爬虫比人类检索数据的速度和深度要快得多,它们可能会(有时确实会)对网站的性能产生严重影响。服务器可能会因为试图跟上快速请求的数量而崩溃。
这就是为什么需要一套礼貌政策,一方面由爬虫程序的编程和爬取的情节控制,另一方面由 robots.txt 文件控制。
搜索引擎抓取新内容进行索引和重新抓取索引中现有页面的速度越快,内容就越新鲜。
如何取得平衡?这才是最难的部分。
假设一下,Google 想要全面报道新闻和时事,决定不顾任何礼貌,每天(甚至每周)尝试抓取整个纽约时报网站。抓取工具很可能会用尽所有带宽。这意味着由于带宽占用,没有人能够在线阅读报纸。
值得庆幸的是,现在除了礼貌因素之外,我们还有Google Search Console,可以通过它来控制抓取网站的速度和频率。
32 年的网络爬行改变了什么?
好的,正如我所料,我们已经讨论了很多内容。
互联网和万维网确实发生了许多变化 – 但爬行部分似乎仍然受到同样的老问题的阻碍。
话虽如此,不久前,我看到了 Bing 机器学习领域的研究员 Andrey Kolobov 的演讲。他创建了一种算法,可以在绘制抓取内容时平衡带宽、礼貌和重要性问题。
我发现它信息量很大,出奇地简单明了,而且解释起来也相当容易。即使你不懂数学,不用担心,你仍然会知道他是如何解决这个问题的。你还会再次听到“重要性”这个词。
基本上,正如我之前关于抓取边界上的 URL 所解释的那样,在抓取之前,超链接分析非常重要,实际上这可能是抓取速度如此之快的原因。您可以在此处观看他的简短演示视频。
现在让我们来了解一下互联网现在的情况,以及网络、5G 和增强内容格式是如何发展起来的。
结构化数据
从一开始,网络就是一片非结构化数据的海洋。这就是它被发明出来的方式。而且,随着数据量每天仍呈指数级增长,搜索引擎面临的挑战是必须抓取并重新抓取索引中的现有文档,以分析和更新是否有任何更改,从而保持索引的新鲜度。
这是一项艰巨的任务。
如果数据是结构化的,那么事情就会简单得多。事实上,很多数据都是结构化的,因为结构化数据库驱动着很多网站。但内容和展示当然是分开的,因为内容必须以纯 HTML 格式发布。
多年来,据我所知,人们尝试过许多自定义提取器来将 HTML 转换为结构化数据。但大多数情况下,这些尝试都是非常脆弱的操作,非常费力,而且很容易出错。
另一个彻底改变游戏规则的因素是,早期的网站是手工编码的,并且是为笨重的老式台式机设计的。但现在,用于检索网页的各种外形尺寸的数量已经极大地改变了网站必须针对的显示格式。
正如我所说,由于网络固有的挑战,谷歌等搜索引擎可能永远无法抓取和索引整个万维网。
那么,有什么替代方法可以大大改善这一流程呢?如果我们让爬虫继续执行其常规工作并同时提供结构化数据馈送,结果会怎样?
在过去十年中,这个想法的重要性和实用性不断增长。对许多人来说,这仍然是一个相当新的想法。但是,WebCrawler 的发明者 Pinkerton 早在 20 年前就在这方面遥遥领先。
他和我讨论了使用特定领域的 XML 源来标准化语法的想法。当时,XML 还是一种新事物,被认为是基于浏览器的 HTML 的未来。
之所以称为可扩展,是因为它不像 HTML 那样是一种固定格式。XML 是一种“元语言”(一种描述其他语言的语言,它允许您为无限多种类型的文档设计自己的自定义标记语言)。其他各种方法被吹捧为 HTML 的未来,但无法满足所需的互操作性。
然而,有一种方法确实引起了广泛关注,即 MCF(元内容框架),它引入了知识表示领域(框架和语义网络)的思想。其思想是以有向标记图的形式创建一个通用数据模型。
是的,这个想法后来被称为语义网。我刚才描述的是知识图谱的早期愿景。顺便说一下,这个想法可以追溯到 1997 年。
尽管如此,2011 年一切都开始步入正轨,Bing、Google、Yahoo 和 Yandex 共同创立了 schema.org。其理念是为网站管理员提供统一的词汇表。不同的搜索引擎可能会以不同的方式使用标记,但网站管理员只需完成一次工作,即可从多个标记使用者那里获得好处。
好吧——我不想过多地谈论结构化数据对 SEO 未来的重要性。这必须再写一篇文章。所以,我会在另一个时间详细讨论这个问题。
但您可能已经看到,如果谷歌和其他搜索引擎无法抓取整个网络,那么提供结构化数据以帮助他们快速更新网页而不必反复重新抓取的重要性将产生巨大的差异。
话虽如此,这一点尤为重要,在结构化数据真正发挥作用之前,您仍然需要让您的非结构化数据因其 EAT(专业性、权威性、可信度)因素而得到认可。
云计算
正如我已经提到的,在过去的四十年里,互联网已经从点对点网络发展成为覆盖万维网的移动互联网革命、云计算、物联网、边缘计算和 5G。
向云计算的转变给我们带来了行业术语“互联网云化”。
大型仓库大小的数据中心提供管理计算、存储、网络、数据管理和控制的服务。这通常意味着云数据中心位于水力发电厂附近,以提供所需的大量电力。
边缘计算
现在,“互联网的边缘化”让这一切从距离用户源较远的地方回到了紧挨着用户源的地方。
边缘计算是指位于网络边缘远程位置的物理硬件设备,具有足够的内存、处理能力和计算资源来收集数据、处理数据并在网络其他部分的有限帮助下几乎实时地执行数据。
通过将计算服务置于更靠近这些位置的位置,用户可以享受更快、更可靠的服务和更好的用户体验,而公司则可以更好地支持延迟敏感型应用程序、识别趋势并提供更优质的产品和服务。物联网设备和边缘设备通常可以互换使用。
5G
随着 5G 以及物联网和边缘计算的强大功能,内容的创建和分发方式也将发生巨大变化。
我们已经在各种不同的应用中看到了虚拟现实 (VR) 和增强现实 (AR) 的元素。在搜索领域,情况也不例外。
AR 图像是 Google 的一项自然举措,他们已经研究 3D 图像好几年了,只是在不断测试、测试、再测试。但他们已经将这种低延迟访问融入知识图谱,并以更具视觉吸引力的方式引入内容。
在疫情最严重的时候,如今“数字化加速”的终端用户已经习惯了与谷歌在搜索结果中随处可见的 3D 图像互动。起初是动物(狗、熊、鲨鱼),然后是汽车。
去年,谷歌宣布,在此期间,3D 特色结果的互动次数超过 2 亿次。这意味着标准已经设定,我们都需要开始考虑创造这些更丰富的内容体验,因为最终用户(可能是您的下一个客户)已经期待这种增强型内容。
如果你还没有亲身体验过(甚至在我们这个行业中也不是每个人都体验过),这里有一个非常酷的惊喜。在去年的这段视频中,谷歌将著名运动员引入了 AR 组合。超级明星运动员西蒙·拜尔斯 (Simone Biles) 可以在搜索结果中与她的 AR 自我互动。
物联网
了解了互联网的各个阶段/发展之后,不难看出,以某种方式连接的一切将成为未来的驱动力。
由于许多技术都受到过度炒作,人们很容易将其抛之脑后,认为物联网只是智能灯泡,可穿戴设备只是健身追踪器和手表。但你周围的世界正在以你难以想象的方式逐渐重塑。这不是科幻小说。
物联网和可穿戴设备是两种增长最快的技术和最热门的研究课题,将极大地扩展消费电子应用(尤其是通信领域)。
未来这一次并没有迟到,它已经来了。
我们生活在一个互联的世界,数十亿台计算机、平板电脑、智能手机、可穿戴设备、游戏机甚至医疗设备,甚至整栋建筑都在以数字方式处理和传递信息。
这里有一个有趣的小事实:据估计,连接到物联网的设备和物品的数量已经超过了地球上的人口数量。
回到SEO的未来
我们就到此为止。接下来还有更多内容。
我计划通过一系列每月文章来详细阐述我们现在所熟知的搜索引擎优化,并介绍其基本方面。尽管如此,“SEO”一词在一段时间内还未进入词典,因为“做一些事情以在搜索引擎门户网站上被发现”的家庭手工业在 20 世纪 90 年代中后期开始出现。
在此之前,祝您身体健康、工作高效,并在这些激动人心的科技时代吸收您周围的一切。几周后我将再次回来,带来更多内容。