谷歌 2020 年论文中关于如何成功使用文本生成模型检测低质量内容的关键 SEO 要点。
该标题是故意误导的——但仅限于使用“ChatGPT”一词。
“类似 ChatGPT” 可以立即让读者知道我所指的技术类型,而不是将系统描述为“像 GPT-2 或 GPT-3 这样的文本生成模型”。 (此外,后者确实不那么可点击……)
在本文中,我们将研究 2020 年的一篇较旧但高度相关的 Google 论文“生成模型是页面质量的无监督预测指标:一项大规模研究”。
这篇论文是关于什么的?
让我们从作者的描述开始。他们这样介绍这个主题:
“许多人对神经文本生成器在现实生活中的潜在危险表示担忧,这主要是因为它们能够大规模生成看起来像人类的文本。
经过训练可以区分人为文本和机器生成的文本的分类器最近被用于监控网络上机器生成文本的存在[29]。然而,尽管这些分类器具有不需要标签的诱人特性——只需要一组人类文本和一个生成模型,但很少有人将这些分类器用于其他用途。在这项工作中,我们通过严格的人工评估表明,现成的人机鉴别器可作为页面质量的强大分类器。也就是说,看起来像机器生成的文本往往不连贯或难以理解。为了了解现实生活中页面质量低下的情况,我们将分类器应用于 5 亿个英文网页样本。”
他们实际上是说,他们发现,使用相同的模型生成用于检测基于人工智能的副本的相同分类器可以成功用于检测低质量内容。
当然,这给我们留下了一个重要的问题:
这是因果关系吗(即,系统之所以能发现它是因为它真的很擅长做这件事)还是相关性(即,当前大量的垃圾邮件是否以一种更容易用更好的工具绕过的方式创建)?
在我们探讨这个问题之前,让我们先来看看一些作者的工作和他们的发现。
设置
作为参考,他们在实验中使用了以下内容:
- 两个文本生成模型,OpenAI基于RoBERTa的GPT-2 检测器(使用 RoBERTa 模型和 GPT-2 输出并预测其是否可能是 AI 生成的检测器)和GLTR模型,后者也可以访问顶级 GPT-2 输出并进行类似操作。
我们可以在我从上面的论文中复制的内容上看到这个模型的输出示例:
- 三个数据集Web500M(随机抽样 5 亿个英文网页)、GPT-2 Output(25 万个 GPT-2 文本生成)和 Grover-Output(他们使用预先训练的Grover-Base 模型内部生成了 120 万篇文章,该模型旨在检测假新闻)。
- Spam Baseline是一个在Enron 垃圾邮件数据集上训练的分类器。他们使用这个分类器来确定要分配的语言质量分数,因此如果模型确定某个文档不是垃圾邮件的概率为 0.2,则分配的语言质量 (LQ) 分数为 0.2。
关于垃圾邮件泛滥的补充
我想快速讨论一下作者偶然发现的一些有趣发现。下图显示了其中一个发现(论文中的图 3):

注意每个图表下方的分数很重要。数字接近 1.0 表示内容是垃圾邮件。我们看到,从 2017 年起,低质量文档盛行,2019 年更是激增。
此外,他们发现低质量内容在某些领域的影响比其他领域更大(记住,分数越高,垃圾邮件的可能性就越高)。
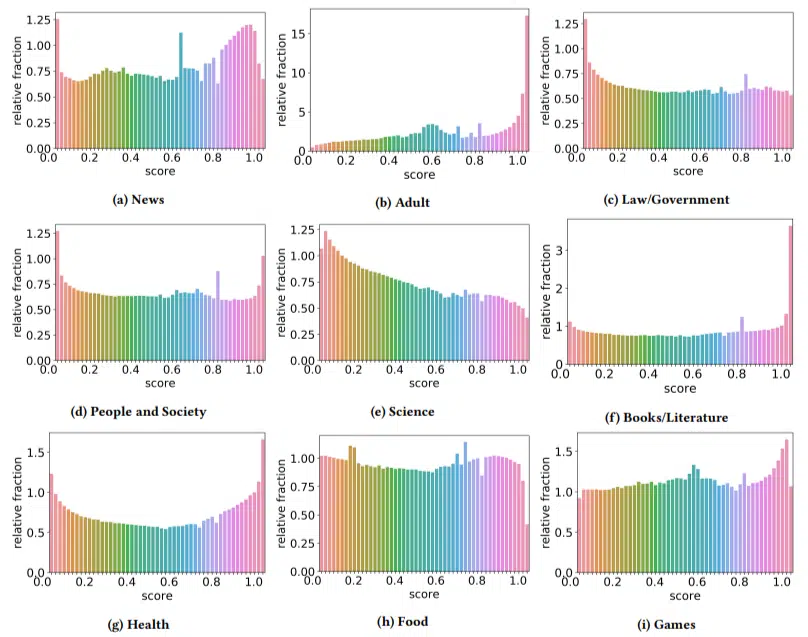
我对这些事情有些困惑。显然,成人的想法是有道理的。
但书籍和文学却有点让人吃惊。健康也是如此——直到作者将伟哥和其他“成人健康产品”网站称为“健康”,将论文农场称为“文学”。
他们的发现
除了我们讨论的行业和 2019 年的激增之外,作者还发现了许多有趣的事情,SEO 可以从中学习并且必须牢记,特别是当我们开始依赖ChatGPT之类的工具时。
- 低质量内容的长度往往较短(最多为 3,000 个字符)。
- 经过训练可以确定文本是否由机器编写的检测系统也擅长对低级内容和高级内容进行分类。
- 他们将我们为排名而设计的内容称为特定的罪魁祸首,尽管我怀疑他们指的是那些我们都知道不应该存在的垃圾。
作者并没有声称这是一个万能的解决方案,而是一个起点,我相信他们在过去几年中已经取得了进展。
关于 AI 生成内容的说明
多年来,语言模型也得到了发展。虽然撰写本文时 GPT-3 已经存在,但他们使用的检测器是基于 GPT-2 的,而 GPT-2 是一个明显较差的模型。
GPT-4 可能即将问世,而谷歌的 Sparrow也将于今年晚些时候发布。这意味着,不仅战场上的双方(内容生成器与搜索引擎)的技术都在不断进步,而且组合也将更容易发挥作用。
谷歌能检测到 Sparrow 或 GPT-4 创建的内容吗?也许吧。
但是如果它是用 Sparrow 生成的,然后通过重写提示发送给 GPT-4,那会怎样呢?
需要记住的另一个因素是,本文中使用的技术基于自回归模型。简而言之,他们根据单词之前的单词预测该单词的得分,来预测该单词的得分。
随着模型变得越来越复杂,并开始一次性创造出完整的想法,而不是一个词接着一个词,人工智能检测可能会失误。
另一方面,对垃圾内容的检测应该逐步升级——这可能意味着唯一能够获胜的“低质量”内容是人工智能生成的。