想要了解机器学习如何影响搜索?了解 Google 如何在搜索中使用机器学习模型和算法。
说到机器学习,有一些广泛的概念和术语是每个从事搜索的人都应该知道的。我们都应该知道机器学习的应用领域,以及存在的不同类型的机器学习。
继续阅读,以更好地了解机器学习如何影响搜索、搜索引擎在做什么以及如何识别机器学习在起作用。让我们从几个定义开始。然后我们将讨论机器学习算法和模型。
机器学习术语
以下是一些重要的机器学习术语的定义,其中大部分将在本文的某个部分讨论。这并不是一份涵盖所有机器学习术语的综合词汇表。如果您需要,Google在此处提供了一个很好的词汇表。
- 算法:对数据进行数学运算以产生输出。针对不同的机器学习问题,有不同类型的算法。
- 人工智能 (AI):计算机科学的一个领域,专注于使计算机获得复制或受人类智能启发的技能或能力。
- 语料库:书面文本的集合。通常以某种方式组织。
- 实体:独特、单一、定义明确且可区分的事物或概念。您可以大致将其视为名词,但其含义比名词要宽泛一些。特定色调的红色就是一个实体。它是独一无二的,因为没有其他颜色与它完全相同,它是定义明确的(想想十六进制代码),它是可区分的,因为您可以将它与任何其他颜色区分开来。
- 机器学习:人工智能的一个领域,专注于创建算法、模型和系统来执行任务,并且通常在无需明确编程的情况下改进自身执行该任务的能力。
- 模型:模型经常与算法混淆。除非您是机器学习工程师,否则这种区别可能很模糊。本质上,区别在于算法只是产生输出值的公式,而模型则是该算法在针对特定任务进行训练后产生的结果的表示。因此,当我们说“BERT 模型”时,我们指的是针对特定 NLP 任务进行训练的 BERT(哪个任务和模型大小将决定哪个特定的 BERT 模型)。
- 自然语言处理(NLP):描述处理基于语言的信息以完成任务的工作领域的通用术语。
- 神经网络:一种模型架构,灵感来自大脑,包括一个输入层(信号进入的地方——对于人类来说,你可以认为它是触摸物体时发送到大脑的信号)、多个隐藏层(提供许多不同的路径,输入可以调整以产生输出)和输出层。信号进入,测试多个不同的“路径”以产生输出层,并被编程为趋向于更好的输出条件。从视觉上看,它可以表示为:
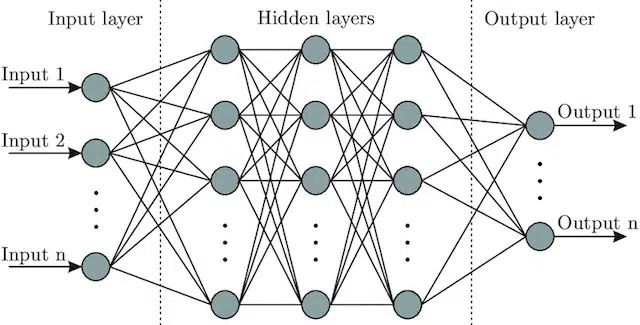
人工智能与机器学习:有什么区别?
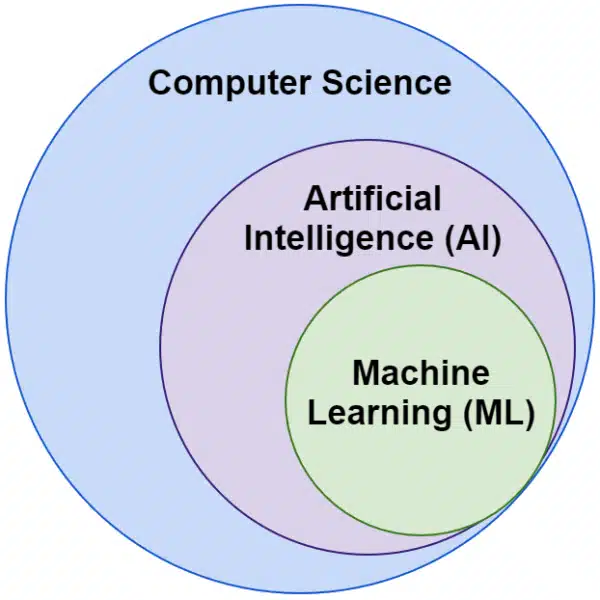
我们经常听到人工智能和机器学习这两个词互换使用。它们并不完全相同。
人工智能是让机器模仿智能的领域,而机器学习是追求无需为某项任务明确编程即可学习的系统。
从视觉上来说,你可以这样想:
谷歌的机器学习相关算法
所有主流搜索引擎都以一种或多种方式使用机器学习。事实上,微软正在取得一些重大突破。Facebook 等社交网络也通过 Meta AI 和 WebFormer 等模型实现了这一突破。
但本文的重点是 SEO。虽然 Bing 是一家搜索引擎,在美国市场占有 6.61% 的份额,但在本文中我们不会重点介绍它,因为我们将探讨流行且重要的搜索相关技术。
Google 使用了大量机器学习算法。你、我,或者任何 Google 工程师都不可能了解所有算法。除此之外,许多算法只是搜索领域的无名英雄,我们不需要全面探索它们,因为它们只是让其他系统运行得更好。
就上下文而言,这些将包括如下算法和模型:
- Google FLAN – 它只是加速了学习从一个领域转移到另一个领域的过程,并降低了计算成本。值得注意的是:在机器学习中,领域不是指网站,而是指它完成的任务或任务集群,例如自然语言处理 (NLP) 中的情绪分析或计算机视觉 (CV) 中的对象检测。
- V-MoE——该模型的唯一任务是允许使用较少的资源训练大型视觉模型。正是这样的发展通过扩展技术能力来推动进步。
- 子伪标签——该系统可提高视频中的动作识别能力,协助完成各种与视频相关的理解和任务。
这些都不会直接影响排名或布局。但它们会影响 Google 的成功程度。
现在让我们来看看与 Google 排名相关的核心算法和模型。
RankBrain
这就是一切的开始——将机器学习引入谷歌的算法。
RankBrain 算法于 2015 年推出,应用于 Google 之前未曾见过的查询(占 15%)。到 2016 年 6 月,该算法已扩展到涵盖所有查询。
继蜂鸟和知识图谱等重大进展之后,RankBrain 帮助 Google 从将世界视为字符串(关键字和单词和字符集)扩展到事物(实体)。例如,在此之前,Google 基本上会将我居住的城市(维多利亚,BC)视为两个经常同时出现的单词,但也经常单独出现,并且当它们同时出现时,可能但并不总是意味着不同的东西。
在 RankBrain 之后,他们将 Victoria, BC 视为一个实体 – 可能是机器 ID(/m/07ypt) – 因此即使他们只点击“Victoria”这个词,如果他们能够建立上下文,他们就会将其视为与 Victoria, BC 相同的实体。
有了它,他们就能“看到”关键词以外的意义,就像我们的大脑一样。毕竟,当你读到“我附近的披萨”时,你是理解了三个单词的意思,还是在脑海中想象出了披萨的样子,并理解了你所在的位置?
简而言之,RankBrain 帮助算法将信号应用于事物而不是关键词。
BERT
BERT(来自Transformer的双向编码器表示)。
随着2019 年BERT 模型引入谷歌算法,谷歌对概念的理解从单向转变为双向。
这不是一个平凡的变化。
谷歌在 2018 年宣布开源 BERT 模型时附带的视觉图有助于描绘这一画面:
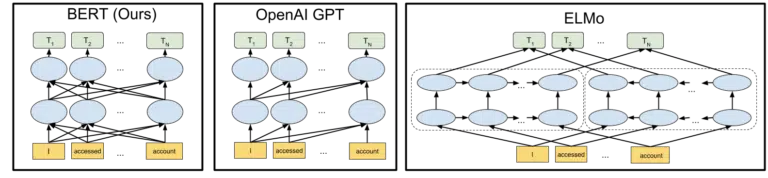
无需详细了解机器学习中 token 和 transformer 的工作原理,只需查看这三幅图和箭头,并思考在 BERT 版本中,每个单词如何从两边的单词(包括多个单词)中获取信息,就足以满足我们的需求。
以前,模型只能从一个方向上应用来自单词的洞察力,而现在,它们可以从两个方向上获得基于单词的上下文理解。
一个简单的例子可能是“汽车是红色的”。
只有在 BERT 被正确理解为红色之后,汽车的颜色才会被理解,因为直到那时,“红色”这个词才出现在“汽车”这个词之后,而该信息才被发回。
顺便说一句,如果您想使用 BERT,GitHub 上提供了各种模型。
拉美裔美国人发展协会
LaMDA尚未正式部署,于 2021 年 5 月在 Google I/O 大会上首次宣布。
需要澄清的是,当我写“尚未部署”时,我的意思是“据我所知”。毕竟,我们在 RankBrain 被部署到算法中几个月后才发现它。话虽如此,一旦部署,它将是革命性的。
LaMDA 是一种对话语言模型,它似乎超越了当前最先进的技术。
LaMDA 的重点主要有两个方面:
- 提高对话的合理性和针对性。本质上,就是确保聊天中的回复既合理又具体。例如,对于大多数问题,“我不知道”的回答是合理的,但并不具体。另一方面,对于“你好吗?”这样的问题的回答,即“我喜欢在雨天喝鸭汤。这很像放风筝。”非常具体,但不太合理。LaMDA
有助于解决这两个问题。 - 当我们交流时,很少是线性对话。当我们考虑讨论可能从哪里开始和在哪里结束时,即使讨论的是一个单一主题(例如,“为什么我们本周的流量下降了?”),我们通常也会讨论到我们无法预测的不同主题。
任何使用过聊天机器人的人都知道,它们在这些情况下表现糟糕。它们不能很好地适应,也不能很好地将过去的信息带入未来(反之亦然)。LaMDA
进一步解决了这个问题。
以下是来自 Google 的一个示例对话:

我们可以看到它的适应能力远比人们对聊天机器人的预期要好得多。
我看到 Google Assistant 中实现了 LaMDA。但如果我们仔细想想,增强理解查询流程在个人层面如何运作的能力无疑将有助于定制搜索结果布局,以及向用户呈现额外的主题和查询。
基本上,我很确定我们会看到受 LaMDA 启发的技术渗透到非聊天搜索领域。
凯尔姆
上面我们在讨论 RankBrain 时提到了机器 ID 和实体。而 2021 年 5 月发布的 KELM 则将其提升到了一个全新的水平。
KELM 诞生的初衷是为了减少搜索中的偏见和有害信息。由于它基于可信信息(Wikidata),因此可以很好地用于此目的。
KELM 与其说是一个模型,不如说是一个数据集。基本上,它是机器学习模型的训练数据。对于我们的目的而言,更有趣的是,它告诉我们 Google 处理数据的方法。
简而言之,谷歌采用了英文 Wikidata 知识图谱,它是三元组(主题实体、关系、对象实体(汽车、颜色、红色))的集合,并将其转换为各种实体子图并将其语言化。这在图像中最容易解释:
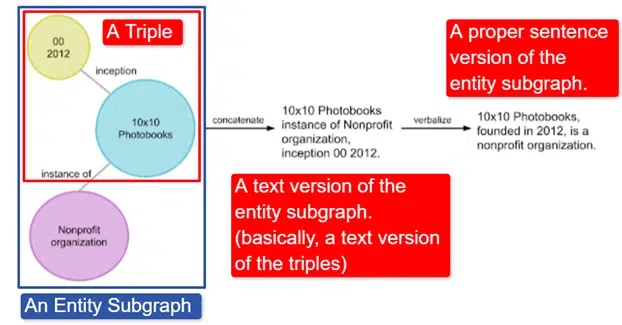
在这张图片中我们看到:
- 该三元组描述了个人关系。
- 实体子图映射与中心实体相关的多个三元组。
- 实体子图的文本版本。
- 正确的句子。
然后其他模型可以使用它来帮助训练它们识别事实并过滤有害信息。
Google 已将语料库开源,可在 GitHub 上找到。如果你想了解更多信息,查看他们的描述将有助于你了解它的工作原理和结构。
妈妈
MUM 也于 2021 年 5 月的 Google I/O 大会上宣布。
尽管它具有革命性,但描述起来却很简单。
MUM 代表多任务统一模型,它是多模式的。这意味着它“理解”不同的内容格式,如测试、图像、视频等。这使其能够从多种模式中获取信息并做出响应。
另外:这不是 MultiModel 架构的第一次使用。它是由 Google于 2017 年首次提出的。
此外,由于 MUM 以事物而非字符串为依据,因此它可以跨语言收集信息,然后以用户自己的语言提供答案。这为信息访问带来了巨大改进,尤其是对于那些使用互联网上不受欢迎的语言的人来说,但即使是英语使用者也将直接受益。
Google 举的例子是一位想要攀登富士山的徒步旅行者。一些最好的提示和信息可能是用日语写的,用户完全无法理解,因为即使他们可以翻译,他们也不知道该如何找到它。
关于 MUM 的一个重要提示是,该模型不仅理解内容,还可以生成内容。因此,它不是被动地将用户引导至结果,而是可以促进从多个来源收集数据并自行提供反馈(页面、语音等)。
对于包括我在内的很多人来说,这可能也是这项技术令人担忧的一个方面。
机器学习在其他领域的应用
我们只谈到了一些你可能听说过的关键算法,我认为这些算法对自然搜索有重大影响。但这还远远不是机器学习应用的全部。
例如,我们还可以问:
- 在广告中,是什么推动了自动竞价策略和广告自动化背后的系统?
- 在新闻中,系统如何知道如何对故事进行分组?
- 在图像中,系统如何识别具体物体和物体类型?
- 在Email中,系统如何过滤垃圾邮件?
- 在翻译中,系统如何处理学习新单词和短语?
- 在视频中,系统如何学习下一步推荐哪些视频?
所有这些问题以及数百甚至数千个其他问题都有相同的答案:
机器学习。
机器学习算法和模型的类型
现在让我们了解一下机器学习算法和模型的两个监督级别——监督学习和无监督学习。了解我们正在研究的算法类型以及在哪里寻找它们很重要。
监督学习
简而言之,通过监督学习,算法可以获得完全标记的训练和测试数据。
也就是说,有人已经努力标记了数千(或数百万)个示例,以便在可靠的数据上训练模型。例如,在x张穿着红色衬衫的人的照片中标记红色衬衫。
监督学习在分类和回归问题中很有用。分类问题相当简单。确定某事物是否属于某个群体。
一个简单的例子就是 Google Photos。
谷歌对我进行了分类,也对各个阶段进行了分类。他们没有手动标记这些照片。但模型将根据手动标记的阶段数据进行训练。任何使用过 Google Photos 的人都知道,他们会定期要求你确认照片和照片中的人物。我们是手动标记者。
曾经使用过 ReCAPTCHA 吗?猜猜你在做什么?没错。你经常帮助训练机器学习模型。
另一方面,回归问题处理的是需要将一组输入映射到输出值的问题。
一个简单的例子是想象一个系统,通过输入平方英尺、卧室数量、浴室数量、距离海洋的距离等来估算房屋的售价。
您能否想到任何其他可能带有多种功能/信号然后需要为相关实体(/站点)分配值的系统?
尽管回归无疑更加复杂,并且包含大量服务于各种功能的单独算法,但它可能是驱动搜索核心功能的算法类型之一。
我怀疑我们正在进入半监督模型——在某些阶段进行手动标记(想想质量评估员),系统收集的信号决定用户对用于调整和制定模型的结果集的满意度。
无监督学习
在无监督学习中,系统会得到一组未标记的数据,并让其自行决定如何处理这些数据。
没有指定最终目标。系统可能会将相似的项目聚集在一起,寻找异常值,找到相互关系等。
当你拥有大量数据,而无法或事先不知道如何使用这些数据时,就可以使用无监督学习。
一个很好的例子可能是谷歌新闻。
Google 会对类似的新闻报道进行聚类,并且还会显示之前不存在的新闻报道(因此,它们是新闻)。
这些任务最好由主要(但并非唯一)无监督模型来执行。这些模型“看到”了之前的聚类或表面化是成功还是失败,但无法将其完全应用于当前未标记的数据(如之前的新闻所述)并做出决策。
它是机器学习中一个非常重要的领域,因为它与搜索有关,特别是随着事物的扩展。
谷歌翻译是另一个很好的例子。它不是以前存在的一对一翻译,即系统经过训练理解英语中的单词x等于西班牙语中的单词y,而是采用较新的技术,寻找两者的使用模式,通过半监督学习(一些标记数据,但大部分没有)和无监督学习改进翻译,将一种语言翻译成一种(对系统而言)完全未知的语言。
我们在上面的 MUM 中看到了这一点,但它也存在于其他论文中,并且模型也很好。
这只是开始
希望这能为机器学习及其在搜索中的应用提供基础。
我未来的文章将不仅仅讨论如何以及在哪里可以找到机器学习(尽管有些文章会)。我们还将深入探讨机器学习的实际应用,您可以使用这些应用来提高 SEO 水平。别担心,在这些情况下,我会为您完成编码,并且通常会提供一个易于使用的 Google Colab 供您使用,帮助您回答一些重要的 SEO 和业务问题。
例如,您可以使用直接机器学习模型来加深对网站、内容、流量等的理解。我的下一篇文章将向您展示如何操作。预告:时间序列预测。